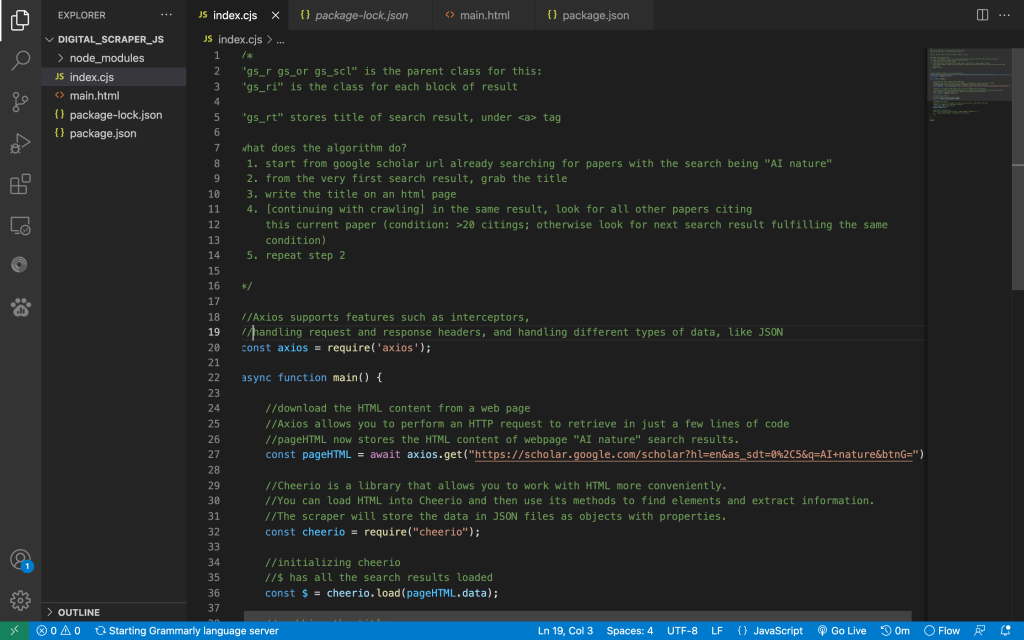
For scraping titles in the digital version, JavaScript became my choice of language as I thought it would allow me more flexibility in accessing many JS/graphic web libraries and just allow better accessibility in general. After debugging some errors I encountered setting up the environment issues in the code, I was able to extract page data from Google Scholar . I chose this source for finding research titles as I believe GS can catch most documents on databases, acting as a general search engine for finding any literature.
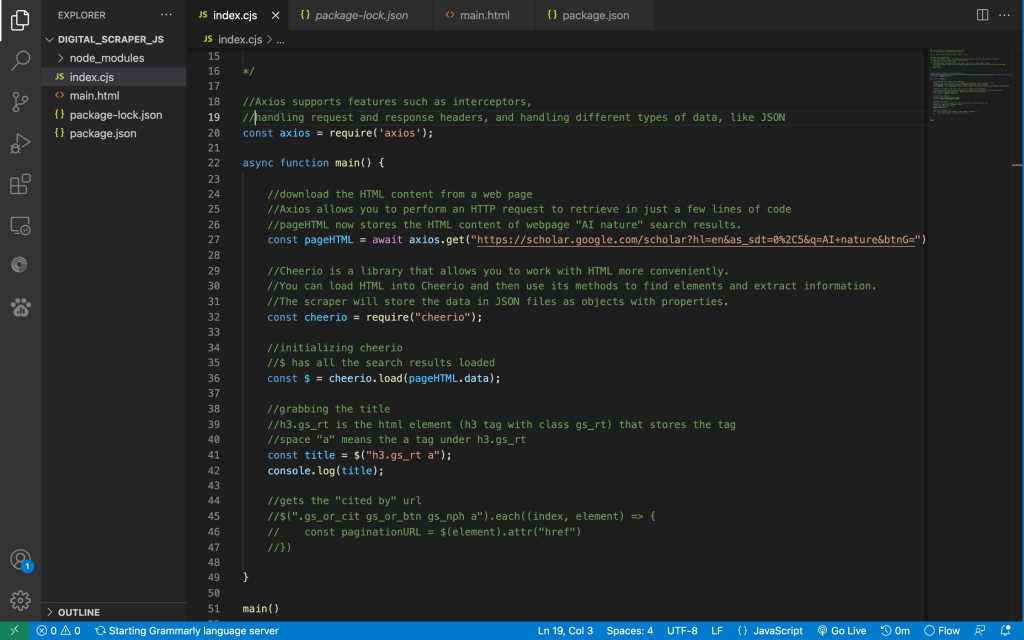
On running the index.cjs script, this was the output in the terminal:
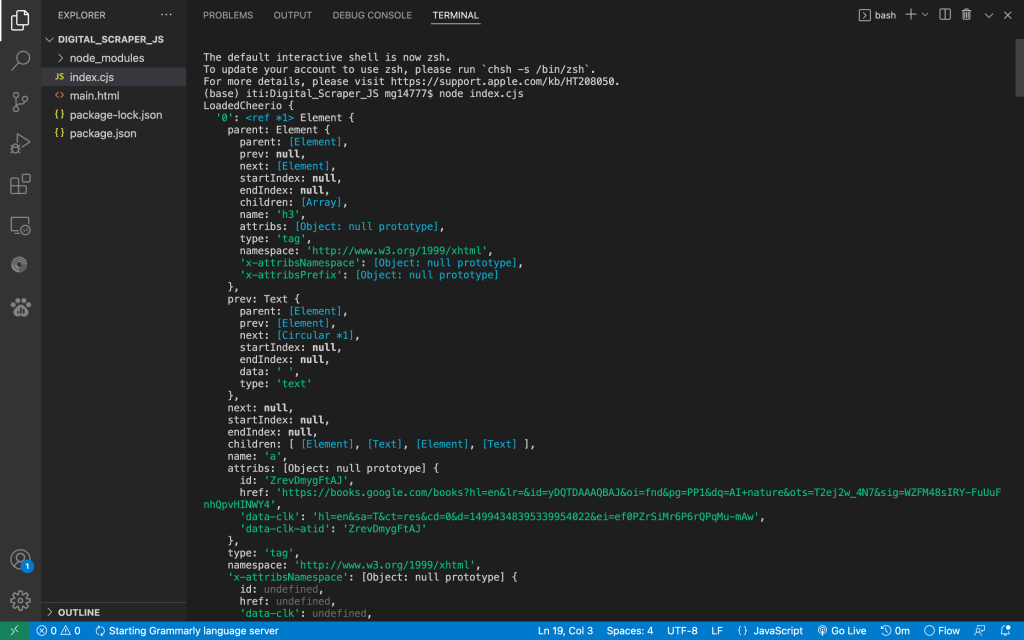
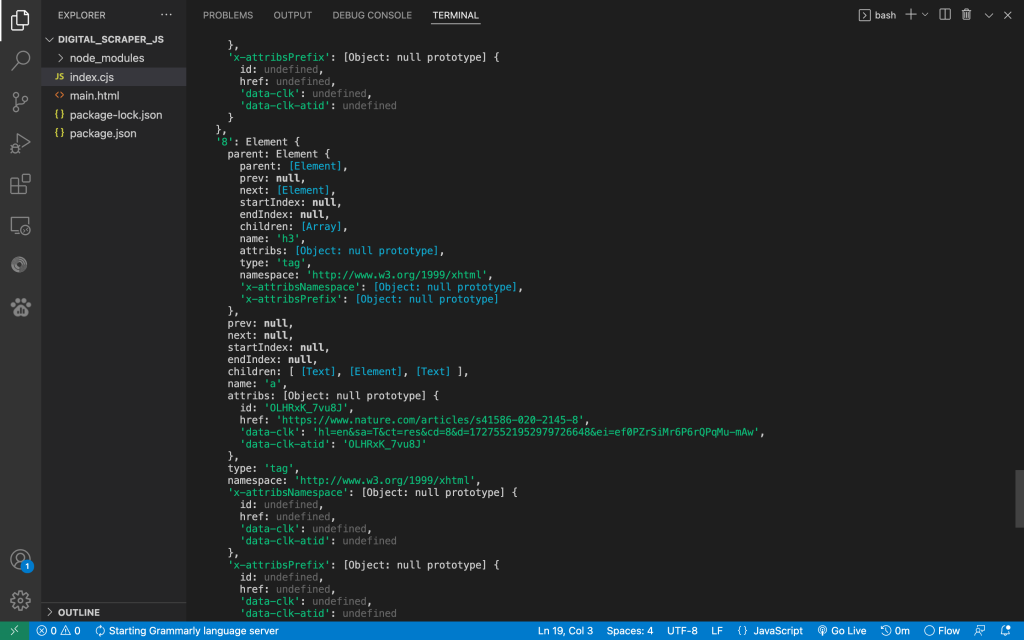
The HTML content fetched here retrieves the link to the title of the research papers. I also need the title itself in text (which is stored in another child element <b>) and the “Cited by….” link.